

Our SQL parsers are among the fastest, if not the fastest, in the world. Once you have something highly optimized, it's very hard to get further tangible gains. Yet I managed to double their speed, and I wouldn't have been able to do so without AI. For the not-so-optimized code, the gains were incredible. Binding is now up to 100x faster and memory consumption down by up to 60x.
I just checked the impact on SQL Tran and it now takes 20 seconds to parse SQL, perform a static analysis pass, and translate full 2.7 million SLOC Oracle schema to Postgres.
The table below shows timing and memory of two of our subsystems:
- Parser: building an in-memory semantic model from the SQL text)
- Binder: part of static analysis that resolves every identifier (name), exposing broken references and telling you "what's what"
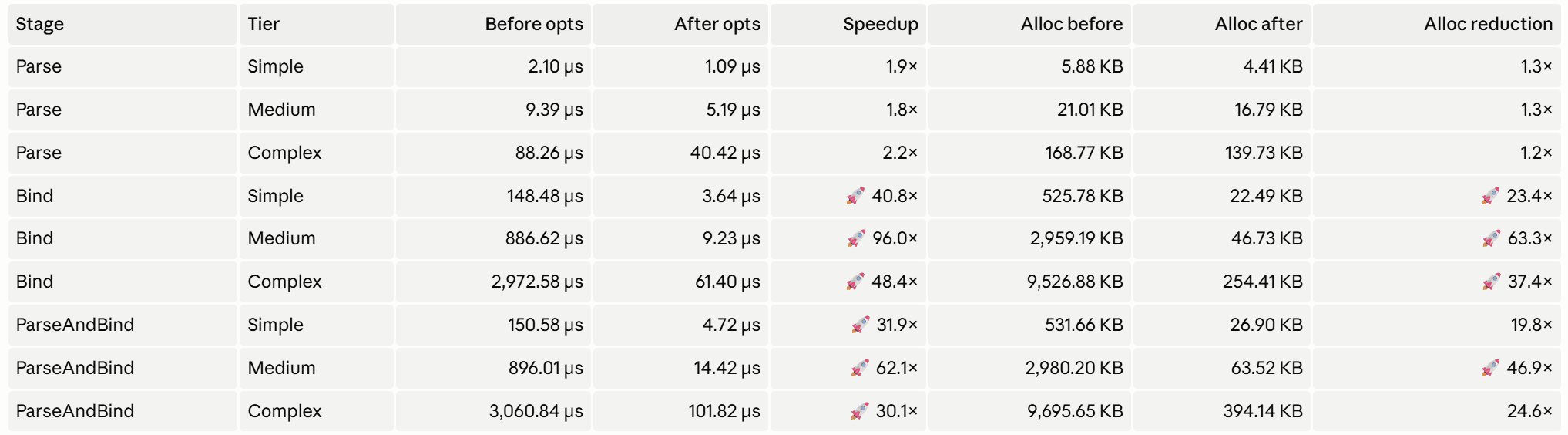
What's measured in the table is parsing and binding of following statements:
- SIMPLE: 120 character SELECT (3 lines, 2-table join)
- MEDIUM: 800 character, 14-line SELECT (4-way join + GROUP BY + ORDER BY)
- COMPLEX: 6300 character, 208-line SELECT (CTEs, recursive CTE, window, lateral, JSONB, etc.)
We have very complete parsers for all major SQL dialects (SQL Server, Oracle, MySQL, Postgres, and more) which matters because, the larger the SQL surface area, the slower the parser. SQL is somewhat ambiguous language and each dialect adds its own quirks. So having a 3-line SELECT statement parse in a single microsecond is a very good outcome. Also, these are not hand-written parsers, they are generated.
If I was able to write a parser generator able to achieve 2 microseconds per parse, why wouldn't I be able to double that speed without AI? Simply, I just wouldn't have the time and the energy to do it. Many of the optimizations I made now were on my bucket list for years. There are always more pressing things and there is a ton of code. Per-database SQL dialects are enormous, so if you want to change something, you will potentially have to touch up a ton of code.
Having your own parser generator instead of using ANTLR (for example) allows you to tweak things to your specific requirements instead of settling for something that works for a wide variety of use-cases you aren't interested in and is therefore pretty slow.
Some of the techniques in the optimization pass (we're using .NET, by the way):
- Lexer (tokenizer) was fast but wasn't optimized for SIMD. As .NET has great improvements in this area, I focused on this and it paid off.
- Of course, any allocations were replaced with spans, where appropriate.
- For context, SQL statements are represented as AST (abstract syntax tree). Basically, each statement is a node, each clause is a child node, and recursively off you go. I had a ton of lists/arrays inside that were eagerly initialized. Converted that to lazily-initialized lists, so just NULL pointers until needed.
- Tree walking was returning a list of matching nodes. Converted that to allocation-free walker. I used Roslyn code-generator to clean up the code and automatically generate switch statement and enumerator to return the next property to dive into.
- Binder nodes had a ton of extraneous fields that seemed like a great idea 10 years ago. All eagerly allocated, most unused now as products I built them for are no longer here. Ruthlessly killed every single field, especially lists, made all the difference. Massive allocation reduction, massive speed increase.
- In-memory representation of tokens consists of token ID and text range. I split that into two arrays as IDs are used all the time and ranges far less. Helps with cache locality.
- Switched expression parser from recursing 10 levels until it gets to the base level into Pratt parser.
- I had the bright idea to ignore setting up AST node parent as I didn't need it for parsing, then recursively setting it later just for binding. That recursive pass is expensive because the tree is sparse. Most properties are never set and it's faster to just set parent as property is assigned. Fixed that with the code generator to keep the codebase clean, got rid of recursive parent setting.
- After I exhausted all ideas I could think of, I remembered that years ago I built a version of the parser for small scripts and it was much faster. Not all scripts are gigabytes in size, in fact almost none are. So parser now automatically uses compact representation for scripts under 64kB and switches to a wider one for larger ones.
I could speed this up further but the following approaches are not free:
- Memory consumption could be fairly reduced via string interning but there is a performance penalty as now you're consulting a hash on every new identifier.
- Memory consumption could be massively reduced by removing string property and there allocation of strings for each identifier. This would also significantly speed things up but would make the code uglier as we'd need to pass the original SQL string through all layers of the code. Don't need that at the moment.
If you made it this far in the super-niche topic of parsing, here are recommendations on how to use AI in coding:
- Sandbox it. That thing is unreliable.
- Give it a quick feedback loop. If it can change the code, re-run the tests, it will self-correct. I had it run on our suite of 27 thousand tests. All of that had to pass before I would commit.
- If you let it write the code, it will do a great job. Next code change will happily destroy an important part it built earlier. Have it commit on each round of changes.
- Don't let it have Github access. As I said, this thing is unreliable. Local commits are fine.
- I had it run dotnet-trace to find the hotspots after I exhausted my bucket list of optimizations. It turns out it can understand the output and use that as a feedback loop.
- Look at what's it doing. If your commits are so large you don't understand what and why is happening, you are up for some serious technical debt down the road.
- Let it generate the inline comments and keep them in code. Even if code is a source of truth, for AI comments will help in the future.
- AI will now, instead of messing up your code, write scripts to do search-replace. Or regex-replace. Or it will even write a Roslyn deep code rewriter just to change the deep pattern-matching code. Marvelous. It would take me forever to update all that code.
What has changed in the recent months? AI is still hallucinating (though less than before). It will always hallucinate, one has to be aware of that limitation. The harness around the LLM is better and now writes simple deterministic scripts when possible. 1M context window is a real game-changer for refactorings such as this one.
Doubling the performance of well-optimized code is rare. Not to mention that increasing the performance of non-optimized code hundredfold was done as a side-quest here. So yes, responsible AI use is highly recommended.
P.S. This same parser is what powers Safe Boundary, our new database security proxy. Early access is open.



